A data engineer makes sure the right data gets to the right place, clean, on time, and at scale. A data scientist takes that data and uses it to build models, run experiments, and answer hard business questions. Different problems, different skill sets, and honestly, a very different day at work.
Both roles are critical. You cannot run a serious AI system without reliable data pipelines, and you cannot get value from those pipelines without solid modeling and analysis. But they solve very different problems, require different skills, and reward different kinds of thinking.
If you are trying to decide which direction to pursue, the question often comes down to this: do you want to build the systems that move and prepare data, or do you want to work with that data to build models and find insights?
This article covers the key differences between Data Science and Data Engineering, what each role actually looks like on an AI team, how the salaries compare, what skills you need, and how to decide which path fits where you want to go.
Key Takeaways
- Data engineers own the pipelines, warehouses, and infrastructure that AI systems run on. Data scientists handle the experimentation, modeling, and insight generation that make those systems useful.
- The core skill difference: data engineers focus on distributed systems, orchestration, and data reliability. Data scientists focus on statistics, machine learning, and experimentation.
- Salary ranges are close, but data engineers currently earn slightly more at most levels because demand is high and qualified candidates are harder to find.
- Both roles are essential in modern AI teams. Engineers prepare data at scale. Scientists consume it to build the intelligence layer.
- Choose Data Engineering if you like building scalable systems. Choose Data Science if you are driven by modeling, experimentation, and analysis.
- The best AI professionals understand both sides, even if they specialize in one.
What AI Teams Actually Look Like Today
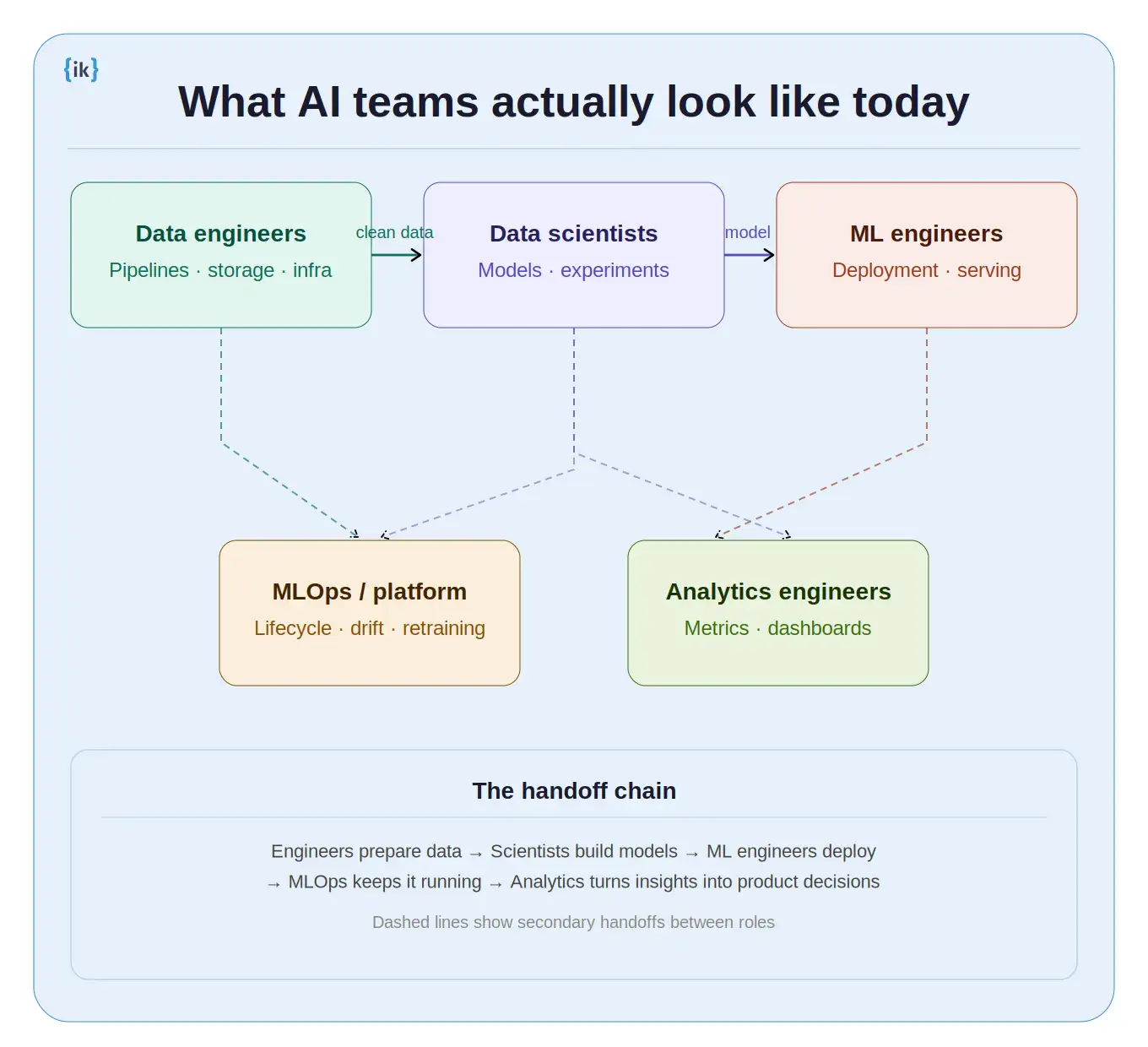
Before comparing the two roles, it helps to see the full picture of how modern AI teams are structured. This matters because data engineers and data scientists do not work in isolation. Each role is a node in a connected system, and understanding the handoffs makes the choice clearer.
A typical AI team includes:
- Data Engineers, who build and maintain pipelines, data lakes, and warehouses
- Data Scientists, who run experiments, build models, and analyze results
- ML Engineers, who take models from experiments into production
- MLOps or Platform Engineers, who manage the ML lifecycle, drift monitoring, and retraining flows
- Analytics Engineers, who work closer to product teams and handle metrics and dashboards
The workflow is not linear. Here is what the handoff actually looks like:
Data engineers build the pipelines that ingest, clean, and structure raw data. Data scientists pick up that clean data to experiment with models. ML engineers take the models that show promise and deploy them to production. MLOps engineers make sure the deployed models keep performing as data changes over time.
When you look at an LLM training pipeline, for example, the Data Engineering layer is enormous. Raw data pours in from logs, user interactions, and third-party sources. It has to be ingested, deduplicated, validated, cleaned, and tokenized before any training starts. A data engineer designs that entire system. Only after it is solid does a data scientist or ML researcher step in to work on the model itself.
Modern AI is not data-science-centric. It is data-infrastructure-centric. The bottleneck in most organizations is not the model. It is the pipeline.
Also Read: Use Cases of AI in Data Engineering
What Data Engineers Do (AI-Focused View) 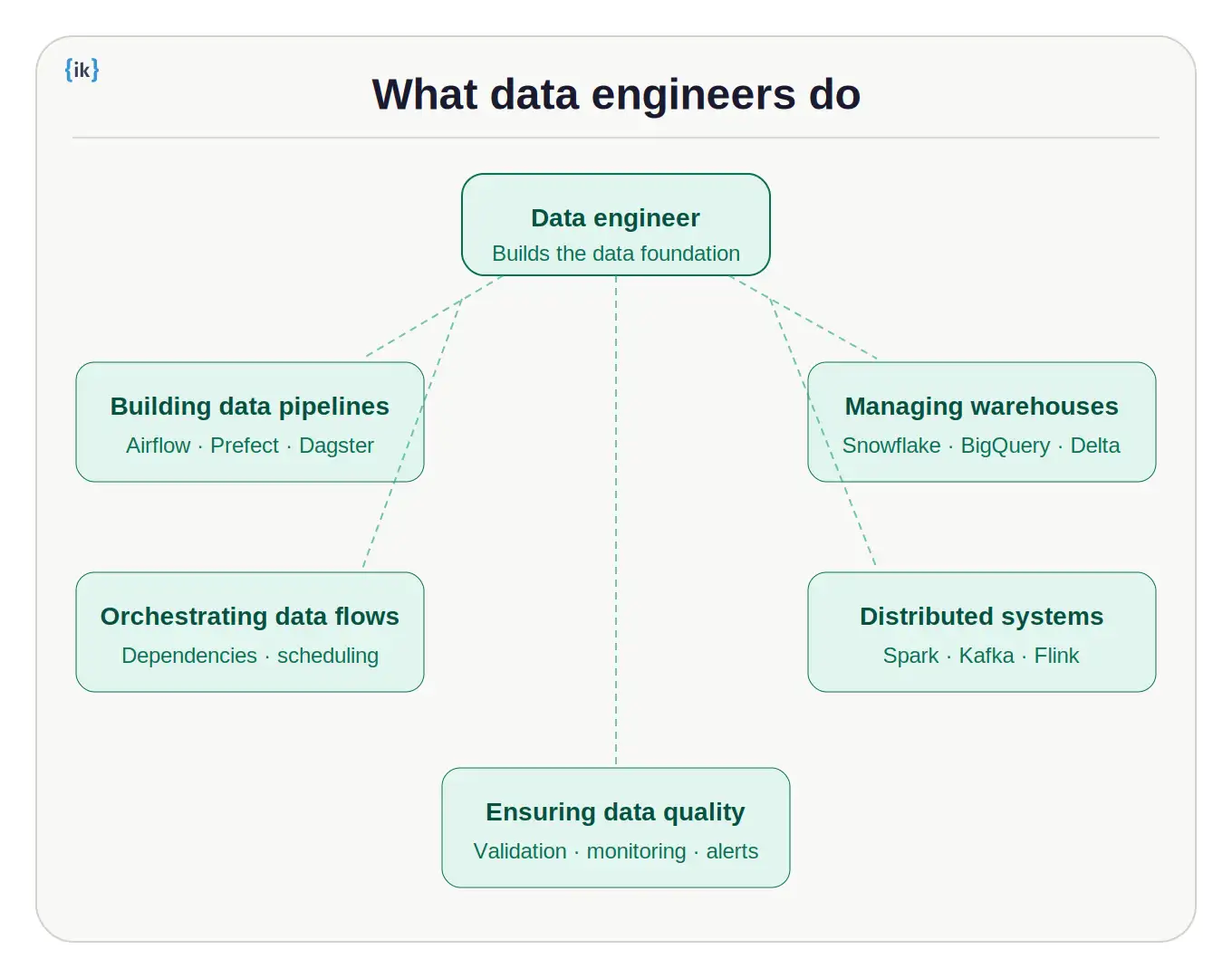
The core mission of a data engineer is to enable scalable, high-quality data for AI models. That sounds straightforward, but in practice, it involves designing and maintaining a lot of interconnected systems.
A data engineer’s core responsibilities include:
- Building data pipelines: Writing orchestration code using tools like Airflow, Prefect, or Dagster to schedule, monitor, and run data jobs reliably. This includes batch pipelines for processing historical data and streaming pipelines for real-time data from Kafka or Kinesis.
- Managing data warehouses and lakes: Deciding where cleaned and raw data live, how it is partitioned, and which storage platform to use. Snowflake, BigQuery, Redshift, and Delta Lake are common choices depending on cost, scale, and query patterns.
- Ensuring data quality: Setting up validation checks so bad data does not silently reach training pipelines. If a column starts showing unexpected nulls, or data distributions shift, a data engineer catches it early.
- Working with distributed systems: Tools like Apache Spark process terabytes of data by distributing work across clusters. A data engineer writes efficient Spark jobs and debugs performance when something takes hours instead of minutes.
- Orchestrating data flows: Making sure dependencies are handled correctly. Data A must be processed before Data B. Model training cannot start until the dataset is ready. The data engineer builds the dependency graph.
Why Data Engineering Matters for AI
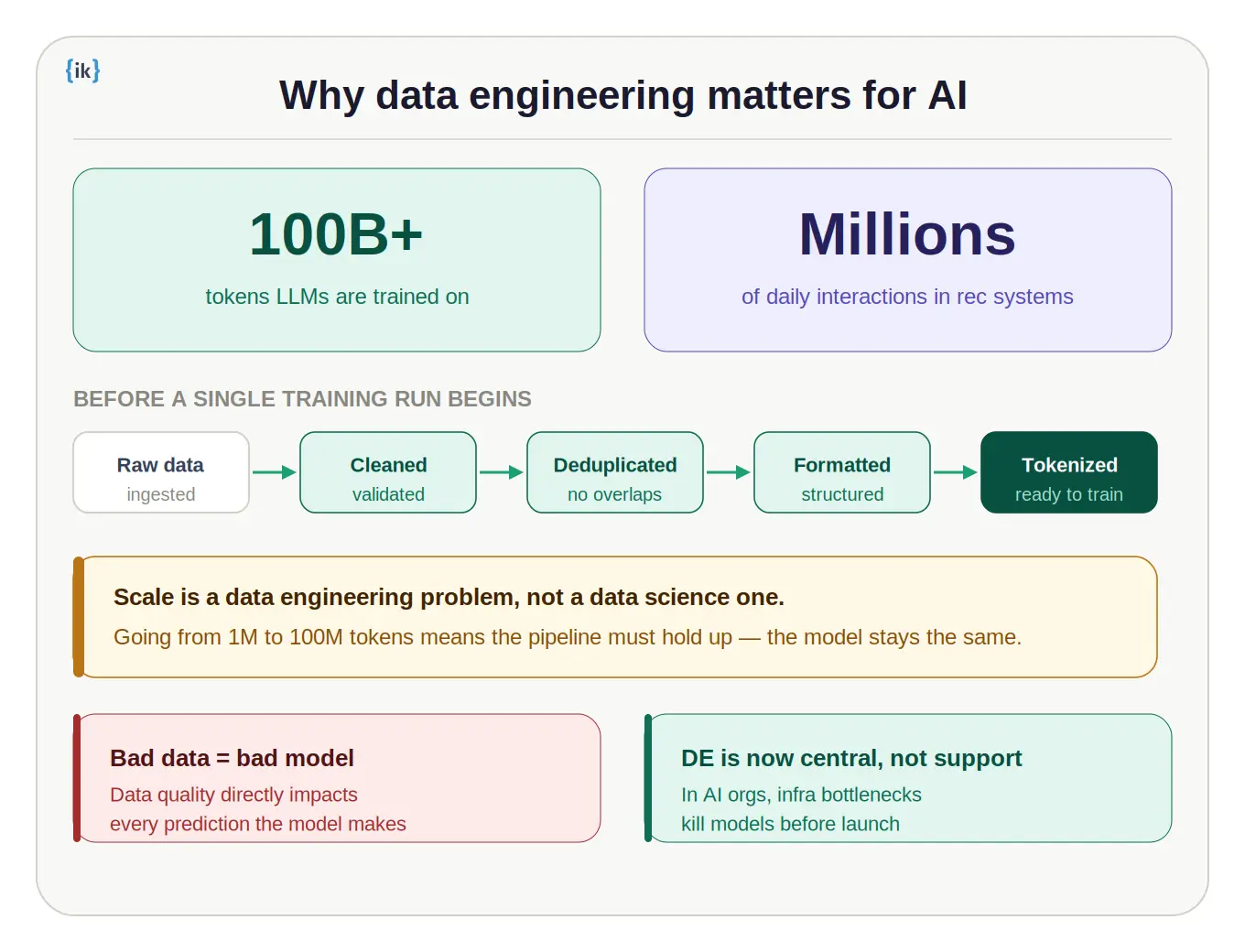
Modern large language models are trained on hundreds of billions of tokens. Recommendation systems process millions of user interactions every day. None of that works without robust, scalable infrastructure underneath it.
Consider what happens when a company wants to fine-tune a language model on its own data. The dataset needs to be clean, consistently formatted, deduplicated, and tokenized before a single training run begins. A data engineer builds those pipelines. When the company wants to scale from fine-tuning on 1 million tokens to 100 million, the pipelines need to hold up. Data quality directly impacts model performance. A model trained on bad data produces bad predictions.
This is why Data Engineering has moved from a supporting role to a central one in AI organizations. The most clever model architecture in the world fails quietly if the data feeding it is unreliable.
What Data Scientists Do (AI-Focused View)
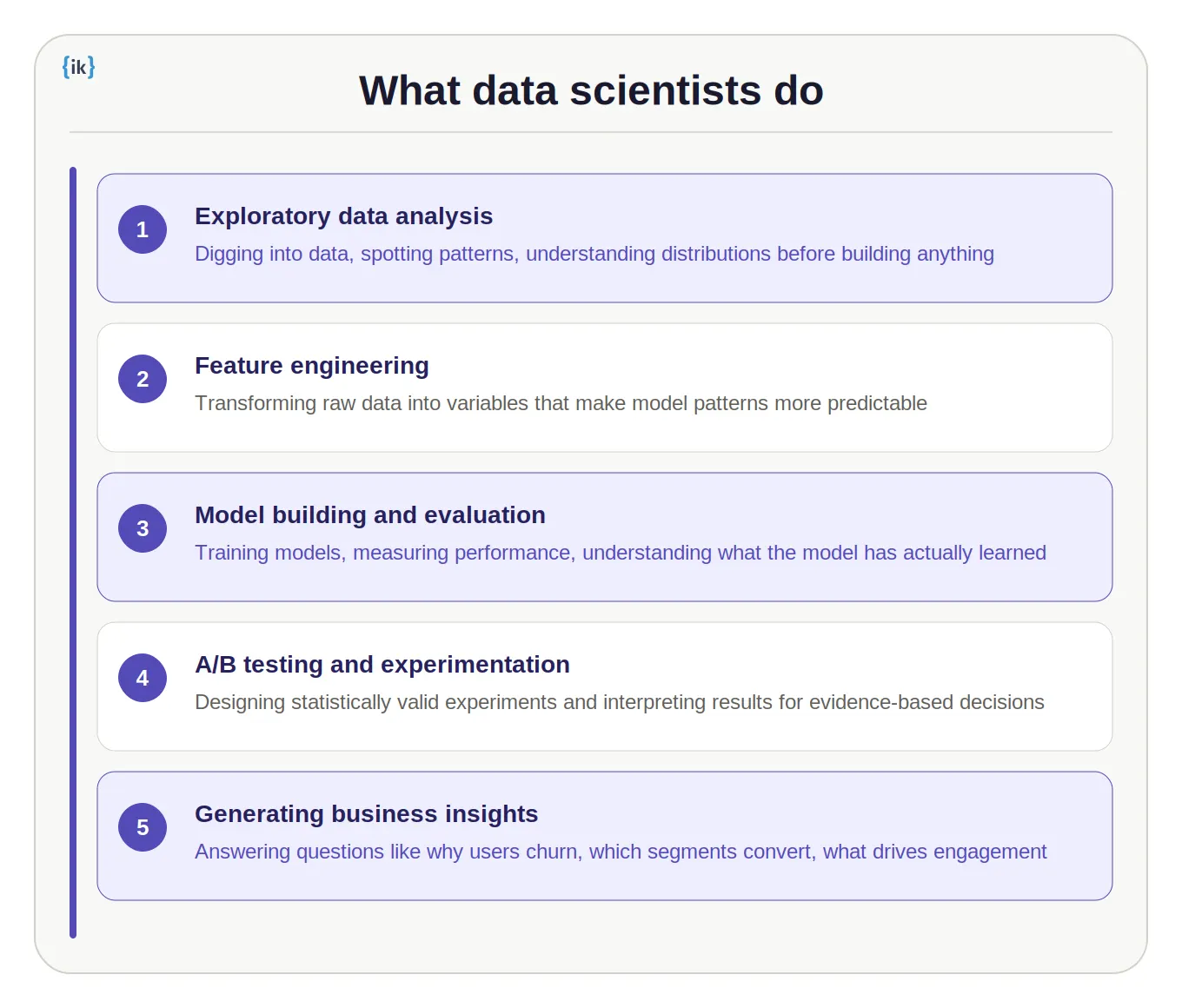
A data scientist’s core mission is to build models, discover patterns, and generate insights from data. Where data engineers focus on infrastructure, data scientists focus on experimentation and analysis.
Core responsibilities include:
- Exploratory data analysis: Digging into datasets, visualizing distributions, identifying outliers, and developing intuition about what the data contains before building anything.
Statistical analysis and hypothesis testing: Using statistical tests to determine whether a pattern is real or just noise. This rigor prevents teams from chasing differences that do not actually matter. - Feature engineering: Creating variables that make patterns more predictable for models. For example, transforming raw transaction records into features like ‘average spend in the last 30 days’ or ‘days since last purchase.’
- Model building and evaluation: Training models, measuring performance, understanding what the model has learned, and identifying where it fails. A data scientist knows the tradeoffs between different algorithms and can spot overfitting.
- A/B testing and experimentation: Designing experiments that are statistically valid, running them correctly, and interpreting results. This is how product teams make evidence-based decisions rather than guessing.
- Generating business insights: Answering questions like ‘why are users churning?’ or ‘which customer segments respond to this campaign?’ These insights drive strategy.
One important clarification: Most Data Scientists do not spend their days building cutting-edge neural networks from scratch. In large AI organizations, they focus on experimentation, model evaluation, and analysis. ML engineers handle the deployment side. The role has become more specialized, which means depth matters more than breadth for data scientists today.
Role of Data Science in AI
Data scientists form the intelligence layer in an AI system. They are the people who decide which models to try, how to evaluate whether they work, and whether the results are trustworthy enough to act on.
The collaboration flow typically looks like this: a data engineer delivers clean, structured data. A data scientist uses that data to run experiments and identify the best model approach. An ML engineer then takes the winning model and deploys it to production. The data scientist continues to monitor model behavior and interpret performance over time.
Data Science vs Data Engineering: Side-by-Side Comparison (AI Lens)
Think about Netflix. The recommendation algorithm that suggests what to watch next is Data Science. Data Engineering is the pipeline that collects viewing history, cleans it, stores it, and delivers it to the algorithm in real time. Without the pipeline, the algorithm has nothing to work with. Without the algorithm, the pipeline produces data that nobody acts on. Both are essential.
Here is how the roles compare across the dimensions that matter most for AI careers:
| Aspect | Data Engineering | Data Science |
| Primary Goal | Enable scalable, reliable data infrastructure | Build models, discover patterns, generate insights |
| Daily Work | Pipeline design, orchestration, and data quality monitoring | Experimentation, statistical analysis, and model building |
| Core Tools | Spark, Kafka, Airflow, dbt, Snowflake, BigQuery | Python, scikit-learn, PyTorch, Jupyter notebooks, R |
| Time Horizon | Long-term (build systems designed to run for years) | Short-term (iterate on experiments week to week) |
| Failure Impact | System-wide, a broken pipeline affects every downstream team | Localized, a bod model affects one product or project |
| AI Role | Enables LLM training pipelines and real-time inference feeds | Develops, evaluates, and improves models |
| Success Criteria | Reliability, throughput, latency, data freshness | Model accuracy, statistical significance, business impact |
| Scalability Focus | Can the system handle 1TB to PB? Will it hold under load? | Focused on model performance, not raw data volume |
| Career Path | Data Engineer to Senior DE to Data Architect | Data Scientist to Senior DS to ML Lead or AI Research |
Data engineers own the reliability of the whole system, while data scientists own the quality of the intelligence layer. A failure in Data Engineering is usually visible and urgent. A failure in Data Science is often subtle and takes time to detect.
For someone choosing between these paths, the practical question is: do you want to be the person who makes sure data flows correctly at scale, or the person who figures out what that data means and how to use it?
Which Path Is Better for an AI Career?
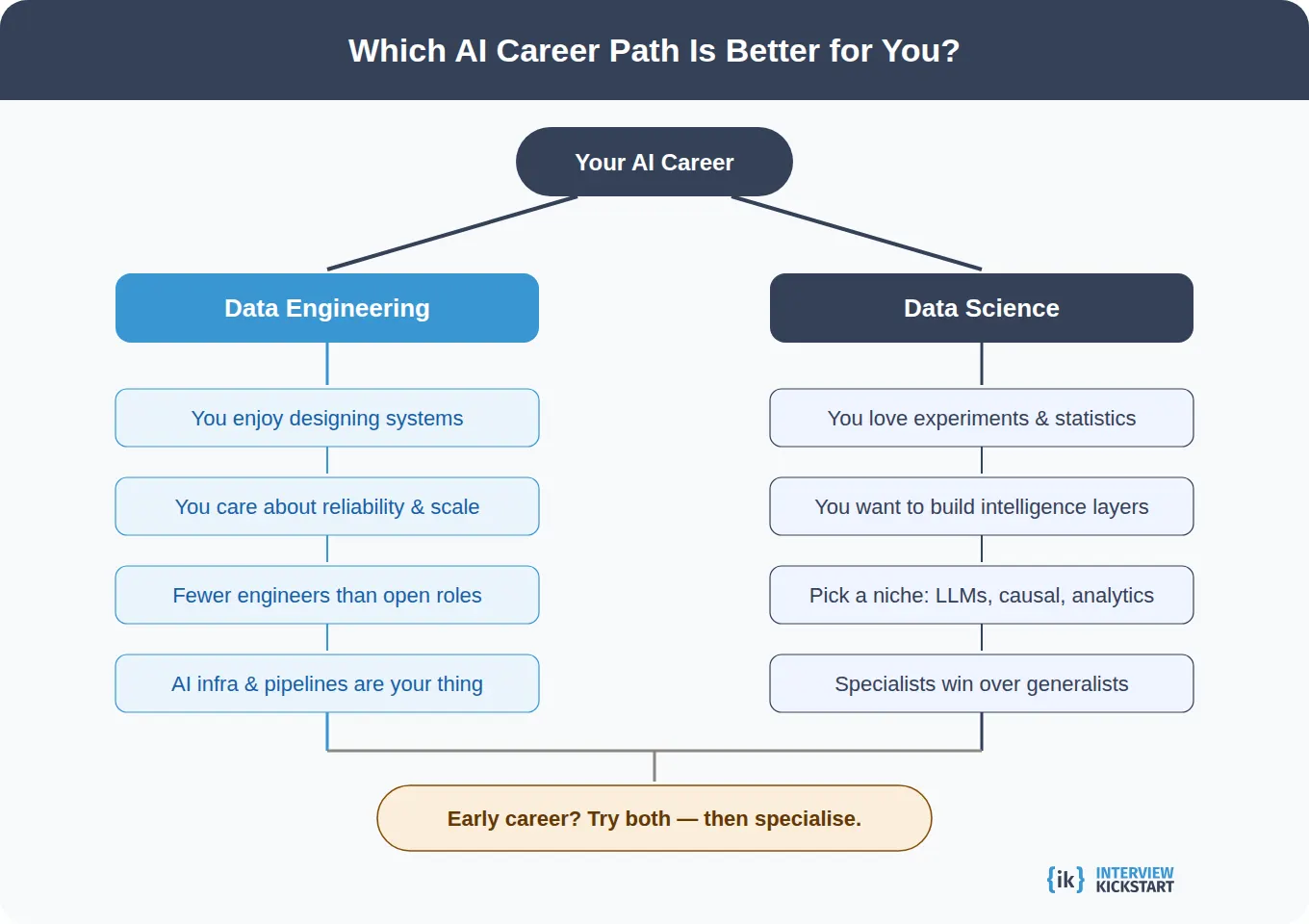
There is no universally better choice. But there is a better choice for you, depending on what kind of problems you want to spend your career solving.
Here is a direct framework to help you decide:
Choose Data Engineering if you enjoy designing systems, thinking about reliability and scale, and solving problems that affect every team that depends on your work. Data engineers are in high demand right now because AI workloads require serious infrastructure and there are fewer qualified engineers than there are open roles.
Choose Data Science if you are driven by experimentation, enjoy working with statistics and models, and want to be directly involved in building the intelligence layer of products. The field has become more specialized, so having a clear focus such as LLM evaluation, causal inference, or product analytics will serve you better than trying to be a generalist.
Consider both paths if you are early in your career. A few years in one role gives you a much stronger foundation when you eventually specialize or pivot. Many successful ML engineers came from either a Data Engineering or Data Science background.
Strengths of Each Path for AI Career Growth
Data Engineering
- Stable, growing demand with a clear promotion path from Data Engineer to Senior Engineer to Data Architect
- Critical for AI deployment at scale, making it hard to eliminate or automate away
- Strong compensation ceiling, particularly at companies building large-scale AI systems
- Skills transfer well across industries since every data-driven company needs reliable pipelines
Data Science
- Broad applicability across industries, from healthcare to fintech to consumer apps
- Higher earning potential in senior AI or research-focused roles at the right companies
- Clear path to ML leadership or AI research for those who specialize deeply
- High demand in model-driven product companies, where experimentation is central to growth
Data Science vs Data Engineering Salary Comparison
Salary is one of the most common reasons people ask about the difference between Data Science and Data Engineering. The short answer: both pay well, and the gap is narrower than most people expect. What matters more is your level of experience, your location, and whether you have specialized skills in AI-heavy domains.
Here is how the salary ranges break down by career stage, based on data from Glassdoor, Indeed, and BLS:
| Career Stage | Data Engineering | Data Science |
| Entry Level (0-2 years) | $59,000 – $101,000 | $70,000 – $123,000 |
| Mid Level (3-5 years) | $63,000 – $109,000 | $81,000 – $141,000 |
| Senior (6+ years) | $71,000 – $121,000 | $92,000 – $163,000 |
| Specialized AI Roles | $98,000 – $136,000 | $170,000 – $210,000 |
Data Engineers currently earn roughly 10 to 15 percent more than data scientists at comparable levels, mainly because demand is outpacing supply for engineers who understand both data infrastructure and AI workloads. However, senior data scientists in specialized research or AI product roles can match or exceed Data Engineering salaries.
Location matters significantly. Salaries in San Francisco, New York, and Seattle run 20 to 40 percent higher than national averages. Specialization also has a larger effect than job title. A data engineer who understands LLM pipelines or real-time streaming will earn more than one who only knows batch processing. A data scientist who specializes in LLM evaluation or causal inference earns more than a generalist.
Key Skills: Data Science vs Data Engineering
The skill sets overlap more than most job postings suggest. Python appears in roughly 57 percent of job postings for both roles, according to 365 Data Science job market research. SQL shows up in around 79 percent of Data Engineering job postings. But the depth and application of these skills differ significantly between the two paths.
Here is a direct comparison of the core skills each role requires:
| Skill Area | Data Engineering | Data Science |
| Programming | Python, Scala, SQL (heavy production use) | Python, R, SQL (analysis and modelling) |
| Data Processing | Spark, Kafla, Flink, streaming systems | Pandas, NumPy, data wrangling libraries |
| ML Frameworks | Basic familiarity for pipeline integration | PyTorch, TensorFlow, scikit-learn (deep expertise) |
| Statistics | Working knowledge for data quality checks | Core competency: hypothesis testing, probability, inference |
| Infrastructure | Cloud platforms, Docker, Kubernetes, CI/CD | Mainly notebook environments and experiment tracking |
| Orchestration | Airflow, Prefect, Dagster (daily use) | Light use for experiment automation |
| Data Storage | Snowflake, BigQuery, Delta Lake, data lake design | Consuming structured data; less emphasis on architecture |
The line between these roles is getting blurry. Data engineers at AI companies are expected to understand how their pipelines interact with model training and inference. Data scientists are expected to understand enough about data infrastructure to communicate clearly with engineering teams and to not build experiments on shaky data foundations.
Neither role requires mastery of the other. But having working familiarity with both sides makes you significantly more effective and more hireable.
Career Path and Growth: What Progression Looks Like
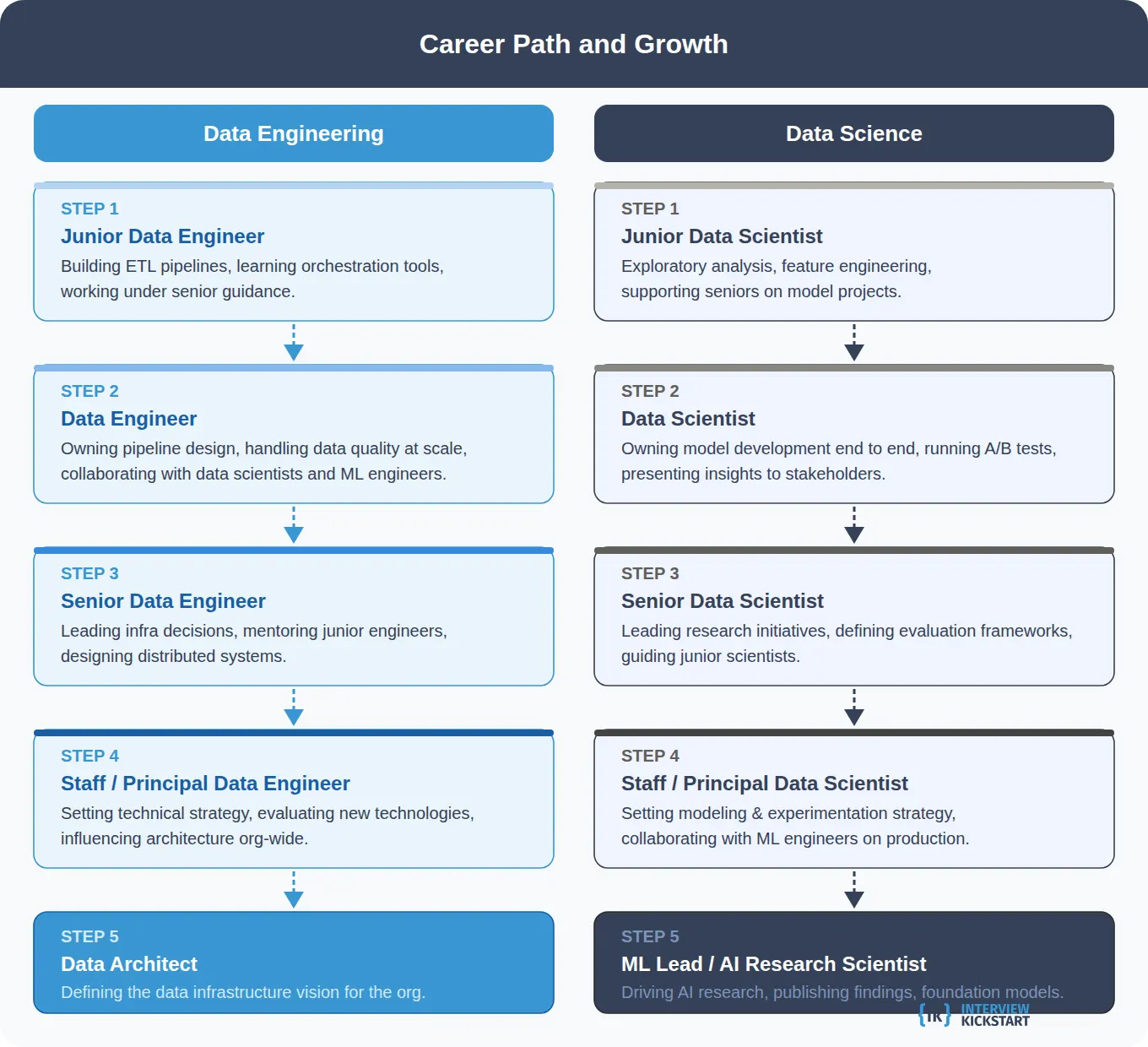
Both paths offer clear upward mobility. Here is what progression typically looks like, along with notes on where the paths can cross.
Data Engineering Career Ladder
- Junior Data Engineer: Building and maintaining ETL pipelines, learning orchestration tools, working under senior guidance
- Data Engineer: Owning pipeline design, handling data quality at scale, collaborating with data scientists and ML engineers
- Senior Data Engineer: Leading infrastructure decisions, mentoring junior engineers, designing distributed systems
- Staff or Principal Data Engineer: Setting technical strategy across teams, evaluating new technologies, influencing architecture org-wide
- Data Architect: Defining the data infrastructure vision for the entire organization
Data Science Career Ladder
- Junior Data Scientist: Exploratory analysis, feature engineering, supporting senior scientists on model projects
- Data Scientist: Owning model development end to end, running A/B tests, presenting insights to stakeholders
- Senior Data Scientist: Leading research initiatives, defining evaluation frameworks, guiding junior scientists
- Staff or Principal Data Scientist: Setting the modeling and experimentation strategy, collaborating with ML engineers on production
- ML Lead or AI Research Scientist: Driving AI research direction, publishing findings, working on foundation model development
Can you transition between the two?
Yes, and it happens regularly. Data engineers who develop a strong interest in modeling often transition into ML engineering or Data Science roles. Data scientists who become frustrated by unreliable data infrastructure often move toward Data Engineering, bringing valuable context about what modeling teams actually need. The key skills that transfer most easily are SQL, Python, and an understanding of the full data lifecycle.
Also Read: From Data Engineer to FAANG Data Engineer: 2026 Career Guide
Conclusion
One role keeps the data flowing reliably at scale. The other turns that data into intelligence. In a well-functioning AI team, these two roles are not competing with each other. They are deeply interdependent.
Data Engineering has become foundational to AI because scalable, reliable pipelines are what make models work in the real world. Data Science remains essential, particularly as it evolves toward specialization in areas like LLM evaluation, causal inference, and product analytics. Generalist Data Science is contracting. Specialized Data Science is growing.
The right path depends on what kind of work energizes you. If you want to build systems, choose Data Engineering. If you want to build models and run experiments, choose Data Science. Either way, understanding how both sides work will make you significantly better at whichever you choose.
If you are serious about building AI-ready Data Engineering skills, Interview Kickstart’s Data Engineering Masterclass covers modern pipeline architecture, GenAI integration, and FAANG-level interview preparation taught by engineers from Google, Salesforce, and Databricks.
FAQs: Data Science vs Data Engineering for an AI Career
Q1. What is the main difference between Data Science and Data Engineering?
Data engineers build the systems that move, store, and prepare data. Data scientists use that prepared data to build models and generate insights. Think of data engineers as the people who build and maintain the roads, and data scientists as the people who use those roads to reach a destination. Both are necessary, but they do fundamentally different work.
Q2. Which pays more: Data Science or Data Engineering?
At most career stages, data engineers earn slightly more, around 10 to 15 percent, because there is strong demand and a smaller talent pool for engineers who understand both data infrastructure and AI workloads. However, senior data scientists in specialized research or AI product roles can match or exceed Data Engineering salaries. The gap narrows significantly at the senior level, and both paths offer strong compensation trajectories.
Q3. Is Data Engineering harder than Data Science?
They are hard in different ways. Data Engineering is hard because you are managing complex distributed systems that have to run reliably at scale, often under unpredictable load. Data Science is hard because statistical rigor, model evaluation, and experimentation design require a different kind of precision. Most people find that one type of challenge resonates more with them, and that intuition is often a good guide for which path to take.
Q4. Can a data engineer become a data scientist?
Absolutely, and the transition is more common than people think. A data engineer who understands the full data lifecycle has a natural advantage when moving into Data Science: they understand how data is structured, where it comes from, and what can go wrong at the pipeline level. The main skills to build for the transition are statistics, machine learning fundamentals, and model evaluation. Starting with courses in these areas while still working as an engineer is a practical way to make the shift.
Q5. Is AI replacing data engineers?
No. If anything, the rise of AI has increased demand for data engineers. Training and running large AI models requires more data infrastructure, not less. What AI tools are doing is automating some of the more routine pipeline tasks, which frees engineers to focus on architecture, reliability, and scalability at a higher level. The engineers who will be most affected are those doing low-complexity, repetitive pipeline work. Engineers who understand AI workloads and modern infrastructure patterns are in a stronger position than ever.
Q6. Do data scientists need to know Data Engineering?
Not in depth, but a working familiarity helps a lot. Data scientists who understand the basics of how pipelines work, how data gets stored and retrieved, and what makes data quality degrade are more effective collaborators and better at designing experiments on solid foundations. You do not need to be able to build a production data warehouse, but knowing what one is and why it matters will make you a better data scientist.
Q7. Which role is better for breaking into AI?
Both are legitimate entry points. Data Engineering is often easier to break into because the roles are more clearly defined and the hiring bar for entry-level positions is more consistent. Data Science roles can be harder to land without a portfolio of projects or a relevant degree, though strong projects can compensate. If your goal is to work on AI systems broadly, Data Engineering gives you faster access to the infrastructure layer where a lot of the real AI work happens. If your goal is model development and experimentation, starting in Data Science is the more direct path.
References
- Data Engineer Salary in US
- AI Data Engineer Salary in US
- Data Scientist Salary in US
- AI Data Scientist Salary in US
Recommended Reads:
- Amazon Data Engineer Salary in the United States
- From Data Engineer to FAANG Data Engineer: 2026 Career Guide
- What Are the Roles and Responsibilities of a Google Data Engineer?
- Amazon Data Scientist Salary
- Facebook Data Scientist Salary Components at Different Levels
- Data Scientist vs Software Engineer Salary

























