Key Takeaways
- Start with clear business requirements and success metrics before looking at any model.
- Evaluate LLMs across four pillars: performance, technical fit, business value, and security/governance.
- Use real data, real users, and a simple weighted matrix to make a data‑driven model choice.
- Bigger is not always better. Optimise for cost, reliability, and long‑term operational fit, not just hype.
The Four Pillars of LLM Selection
When evaluating LLMs, think in terms of four pillars: performance, technical factors, business impact, and security & governance. Ignoring any one of these is how organisations end up with impressive demos and disappointing ROI.
Each pillar has concrete questions you can ask and measurable criteria you can score, which later feed into an evaluation matrix.
1. Performance: Can The Model Actually Do The Job?
The first pillar is performance: how well does the model serve your specific use case. This is more than leaderboard scores; it is about latency, context length, reasoning capability, and reliability on your real data.
Here are some key dimensions to assess.
1. Latency and responsiveness
For real‑time experiences like customer‑facing chatbots or agent assist tools, perceived speed is part of product quality. A model that produces slightly better answers but responds in 8–10 seconds can ruin user experience compared to a slightly “weaker” model that responds in 1–2 seconds.
2. Context length
Context length defines how much information the model can reliably “hold” in a single request, such as long documents, chat histories, or tool outputs. Some frontier models now support contexts in the million‑token range, while smaller or specialised models may sit between roughly 128K and 400K tokens.
3. Reasoning and task complexity
Not every use case needs PhD‑level reasoning. For code generation, complex analytical workflows, or multi‑step decision making, you might require models with stronger reasoning and planning behaviours. For simpler tasks like basic summarisation or straightforward classification, smaller models tuned for that task can be both cheaper and faster.
4. Benchmarking vs. real‑world testing
Public benchmarks and leaderboards are useful for a first filter but should be taken “with a grain of salt.” They rarely reflect your domain, your users, or your edge cases, which is why you must validate models against your own prompts and datasets before making a final choice.

2. Technical Considerations: Latency, Throughput, and Infrastructure
Once a model looks promising from a capability standpoint, you need to check whether it fits your technical constraints and architecture. Technical factors define whether your solution can scale, stay reliable, and integrate cleanly with your environment.
Here are some important aspects to consider.
1. Latency and throughput at scale
Transaction limits (TPS/QPS), per‑minute caps, and rate‑limit policies directly impact user experience and system design. High‑volume use cases need models and providers that offer predictable throughput, or the ability to negotiate higher limits via enterprise agreements.
2. Batch vs. real‑time workloads
Many providers offer distinct pricing and SLAs for batch inference vs. real‑time generation. If you are doing offline document translation, bulk summarisation, or pre‑computation, routing that traffic through batch endpoints can cut costs significantly without hurting UX.
3. Hosting and deployment options
You’ll need to decide whether to consume the model via a hosted API, run it in your own VPC, or self‑host using open‑source weights on your own GPUs. Larger enterprises with strict data residency needs may lean toward VPC‑hosted or on‑prem deployments, while startups often default to fully managed APIs to minimise operational overhead.
4. Integration and API compatibility
Most mainstream providers now expose broadly similar HTTP APIs and SDKs, and many third‑party models deliberately mimic the OpenAI API surface for easier migration. This means in many stacks you can change a base URL and model name while keeping most of your application code unchanged, which is valuable for avoiding vendor lock‑in.

3. Business Lens: Cost, Value, and Vendor Ecosystem
The third pillar shifts the focus from engineering to business value and cost of ownership. Many organisations overspend on GenAI because they only look at the token price, not the full lifecycle cost and realised value.
1. Token pricing and usage patterns
Different models and providers have different input vs. output token pricing, and output tokens often cost more. For verbose tasks such as long‑form content generation or detailed analysis, output-heavy workloads can quickly dominate your bill if not monitored.
2. Total cost of ownership (TCO)
TCO goes beyond API invoices; it includes infra (if self‑hosting), development, integration, monitoring, training, and change management. Many of the widely reported “GenAI disappointments” trace back to ignoring TCO and underestimating the human effort required to deploy and maintain production‑grade systems.
3. Vendor support and ecosystem maturity
Open‑source models can offer flexibility and cost savings, but you must be clear whether you rely on community support, a commercial vendor, or a managed platform. With emerging startups, consider what happens if they are acquired or pivot, and whether you have a clear escape plan or migration strategy.
4. Roadmap alignment and stability
Because AI is moving fast, you want vendors whose product roadmap aligns with your needs over the next 12–24 months, not just today’s shiny release. Stable APIs, predictable deprecation policies, and a cadence of improvements that map to your use cases all matter for long‑term success.

4. Security and Governance: Data, Risk and Compliance
The fourth pillar is security and governance, which is often where good prototypes die before production. You need a deep understanding of how data flows, how it is stored, and what risks arise from model behaviour.
Key questions you need to investigate.
1. Data usage and training policies
Enterprise contracts with major providers often promise that your prompts and outputs are not used to train public models, but you must validate this in the terms and conditions. You should know exactly where your data is stored, who can access it, and whether your organisation receives a dedicated or shared model endpoint.
2. Access control and auditability
In regulated industries, you need audit trails of who used what model, when, and on which data. Role‑based access control, logging, and centralised policy management become table stakes when LLMs are integrated into core workflows.
3. Bias, safety and guardrails
All models inherit bias from their training data and can generate toxic or unsafe content if not properly governed. You should actively test your chosen models with adversarial prompts and “prompt injection” attempts to validate that safety guardrails hold up under realistic misuse scenarios.
4. Regulatory compliance
Healthcare, finance, public sector, and other regulated domains come with their own compliance regimes. Your model choice, deployment topology, and logging strategy must all support the required standards and audits.

Also Read: What is a Large Language Model (LLM)? How LLMs Like GPT Actually Work
Common Pitfalls to Avoid When Choosing an LLM
Before digging into the step‑by‑step framework, it helps to call out the mistakes that cause most LLM initiatives to underperform. Avoiding these early saves months of rework and cost.
Chasing the biggest model by default
“Bigger” often means more expensive, slower, and riskier if your use case doesn’t actually require frontier‑level capabilities. For many enterprise workloads, a smaller, well‑tuned, domain‑aware model delivers better cost‑performance while meeting all functional requirements.
Ignoring total cost of ownership
Teams that focus only on per‑token price or initial POC effort often discover later that support, MLOps, retraining, and user enablement dominate long‑term costs. A realistic TCO view is essential before you commit to a vendor or architecture.
Not testing with real, messy data
Synthetic prompts or cherry‑picked examples make almost any modern LLM look good. The real signal comes from running the model against your own documents, logs, knowledge bases, and user prompts, including edge cases and failure patterns.
Skimming the terms and conditions
Overlooking contractual details about data usage, logging, or cross‑border processing can create legal and reputational risk. Security and legal stakeholders must review and sign off on these details early, not just before go‑live.
Starting from technology instead of business requirements
Picking a model first and then searching for use cases almost guarantees weak business value. Successful teams start from concrete business problems and work backward to the minimal model that can solve them reliably.

A Four‑Step LLM Selection Framework
To make this practical, here is a four‑step framework for selecting and operationalising the right LLM: requirements, evaluation, testing & validation, and deployment & operations. This mirrors the flow of the talk and can be used as a checklist for your organisation.
Step 1: Requirements – Start From the Business Problem
Everything starts with clearly defined requirements. This is where most teams should spend the majority of their time before touching a model API.
Use cases and tasks
Be explicit about what the LLM will do: summarise long reports, power a customer support assistant, generate code, extract fields from documents, or assist analysts with research. Each use case might require different context length, reasoning ability, or latency profiles.
Success metrics
Decide upfront how you’ll measure success: response accuracy, deflection rate in support, time saved per analyst, cost per conversation, or user satisfaction scores. Without quantitative and qualitative metrics, it is nearly impossible to compare models in a meaningful, defensible way.
User experience expectations
Clarify whether interactions are real-time or asynchronous, and what response times are acceptable. Think through UI flows, hand‑offs to humans, and how the LLM integrates with existing systems such as CRMs, ticketing tools, or internal knowledge repositories.
Volume, load, and growth
Estimate expected traffic: requests per second, daily session counts, peak vs. off‑peak usage, and anticipated growth over the next 6–12 months. These inputs determine the scalability and rate‑limit requirements your chosen vendor must satisfy.
Constraints: budget, timeline, skills, and compliance
Capture hard constraints early: budget ceilings, delivery deadlines, regulatory requirements, and the current skill level of your team. If skills are a gap, you may also need to plan for training or bring in external expertise as part of your roadmap.
Step 2: Evaluation – Build a Simple, Weighted Scoring Matrix
Once requirements are clear, you can shortlist candidate models and evaluate them in a structured way. A practical method is to use a weighted evaluation matrix covering at least performance, cost, latency, security, and support.
Here’s how you can set up the matrix:
Define criteria and weights
For each dimension (e.g., performance, cost, latency, security, vendor support), assign a weight reflecting its importance for your project. Mission‑critical applications might heavily weight reliability and security, while experimental tools might optimise for cost and speed of iteration.
Score candidate models
For each candidate LLM, assign scores per criterion based on documentation, early experiments, and vendor conversations. Keep the scale simple (for example, 1–5) to avoid false precision and allow easier comparison.
Compare overall scores and trade‑offs
Aggregate scores to get an overall view, but also inspect where each model is strong or weak. Sometimes a slightly lower overall score might still be the best choice if it excels on the single most important dimension for your use case.
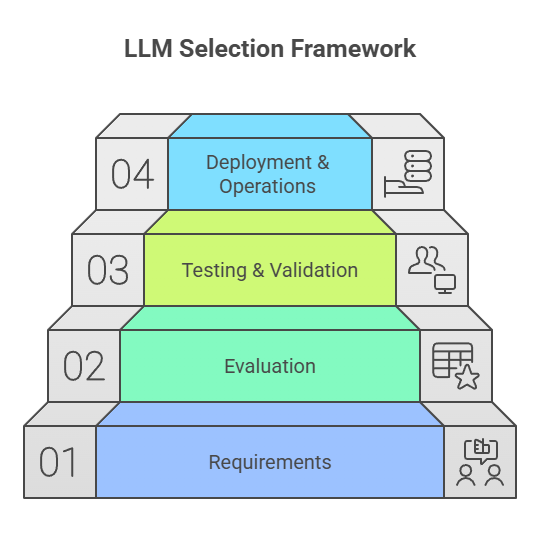
Step 3: Testing and Validation – Use Real Data and Real Users
The next stage is hands‑on testing and validation with real workloads. This is where assumptions from the matrix are either confirmed or disproved. Effective validation includes.
Representative real‑world examples
Use actual documents, customer queries, logs, and internal knowledge articles instead of synthetic examples. Include domain‑specific jargon, messy inputs, and historical failure cases that the current system struggles with.
Edge cases and adversarial prompts
Don’t only test happy paths. Include rare edge cases, ambiguous questions, deliberately adversarial prompts, and attempts to bypass safety constraints to understand the model’s robustness.
Involve real users early
Bring business stakeholders, support agents, analysts, or engineers who will actually use the system into the pilot loop. Their feedback on usefulness, trust, and UX often surfaces issues that raw metrics miss.
Measure both quantitative and qualitative outcomes
Track metrics like accuracy, latency, and cost per request alongside subjective signals like “felt trustworthy,” “reduced manual effort,” or “was easy to use.” Both are necessary to make a robust go/no‑go decision.
Step 4: Deployment and Operationalisation – From Pilot to Production
If testing goes well and you select a model, the final step is turning a successful pilot into a reliable, maintainable production system. This is where architecture, operations, and enablement come together. Here are the key components.
Final architecture and integrations
Solidify your system architecture: orchestration layer, retrieval or tools if applicable, observability, and integration points with existing systems. Ensure that security and governance requirements are embedded into the design, not bolted on later.
Security, governance, and monitoring
Put in place access controls, audit logging, prompt and response logging policies, and monitoring for drift, latency spikes, and error rates. For higher‑risk use cases, consider human‑in‑the‑loop review for a subset of outputs, especially in the early phases.
Training and enablement
Plan structured enablement for engineers, operators, and frontline users so they know how to get the best out of the system and what failure modes to watch for. Good training often makes the difference between a powerful but misunderstood tool and a widely adopted productivity multiplier.
Plan for change and iteration
The LLM landscape is moving quickly, so design for model upgrades and vendor changes. Abstracting model access behind an internal interface or service makes it easier to swap or add models later without rewriting entire applications.
Bringing It All Together
Choosing a large language model is not about picking the model with the most parameters or the most hype; it is about aligning performance, technical constraints, business value, and security into a coherent, data‑driven decision.
By starting from requirements, using a simple evaluation matrix, validating against real data with real users, and planning for operations from day one, you dramatically increase the odds that your GenAI investment delivers real, measurable impact.
Download the LLM Selection Checklist (PDF)
Download the LLM Evaluation Matrix (PDF)
FAQs: How to Choose LLMs
Q1. How do I choose the right LLM for my use case?
Start from the business problem, list specific tasks and success metrics, then evaluate a short list of models on performance, latency, cost, security, and vendor support using a simple weighted matrix.
Q2. Do I always need the largest, most powerful LLM?
No, for many enterprise workloads, a smaller or specialised model is cheaper, faster, and easier to operate while still meeting all accuracy and reasoning requirements.
Q3. What should I test before committing to an LLM in production?
Run the model on your real data and edge cases, involve actual users, measure both quantitative metrics (accuracy, latency, cost) and qualitative feedback (trust, usability), and verify safety and compliance behaviour.
Q4. How do I control costs when using LLMs at scale?
Optimise prompts, use smaller models where possible, route offline workloads to batch inference, monitor token usage closely, and include infra, engineering, and governance in your total cost of ownership calculations.












